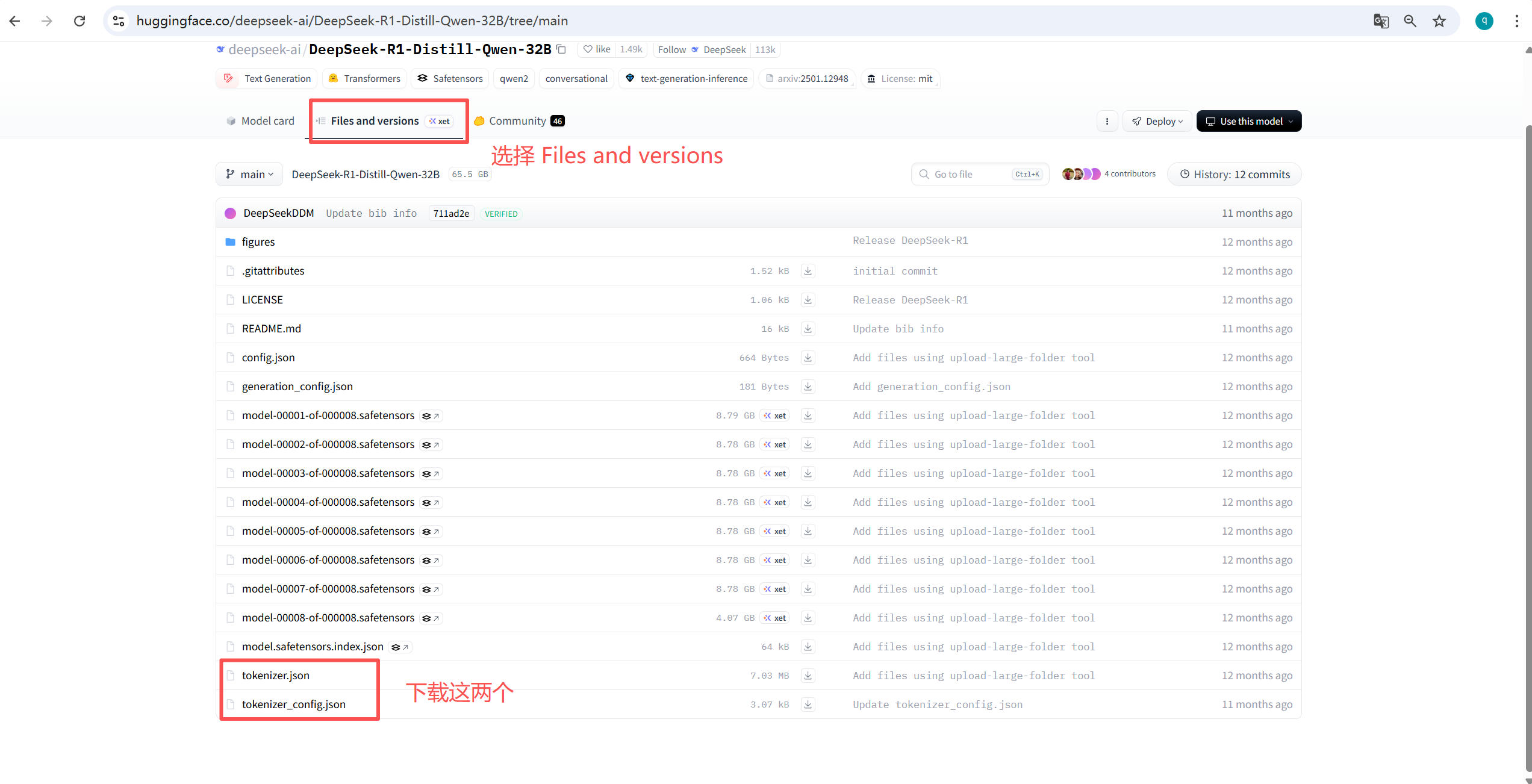
注意:
- 原本打算用 VMware Workstation 来部署,但 VM 不支持 CUDA,所有版本都不支持,目前是17.6
- 本文采用 Windows 11 下使用 WSL 来部署相关环境(为了不污染宿主机本身,随时可以通过移除 wsl 镜像来彻底清理数据),所以:
- 不要在 WSL 里装 nvidia-driver-*
- 不要在 WSL 里禁用 nouveau(WSL 根本没有)
- 确保 windows 已经安装了 NVIDIA 显卡驱动
- Power shell 输入:nvidia-smi 即可看到 GPU 使用情况
- 为什么不安装cuDNN
- 在 WSL2 上,cuDNN 其实不需要单独安装,只要 CUDA toolkit 路径正确,并安装了 PyTorch GPU 版,就已经自带了 cuDNN 依赖。
科普小知识:
如何选择推理框架?
-
- SGLang - 大规模集群部署专家
- Ollama - 轻量级玩家最爱
- vLLM - GPU推理性能王者
- LLaMA.cpp - CPU部署救星
综合考量:
-
- 要极致性能 → 选vLLM
- 要简单易用 → 选Ollama
- 要集群部署 → 选SGLang
- 要CPU运行 → 选LLaMA.cpp
性能对比:
-
- 推理速度:vLLM > SGLang > Ollama > LLaMA.cpp
- 易用程度:Ollama > LLaMA.cpp > vLLM > SGLang
- 硬件要求:vLLM(需GPU) > SGLang > Ollama > LLaMA.cpp
建议:
-
- 单卡或双卡4090用户 → 闭眼入vLLM
- 个人开发者 → Ollama快速上手
- 企业级部署 → SGLang更专业
进入 wsl 并启动 vLLM 推理服务:
# 进入 wsl 虚拟机
wsl -d Ubuntu-22.04
# 切换 root 用户(ubuntu 推荐不要使用 root,因为 root 会有很多地方出问题,比如使用 Miniconda 管理器)
su root
123456
# 激活 python 环境
conda activate deepseek
# 启动命令,后续可做成开机启动
python -m vllm.entrypoints.openai.api_server \
--served-model-name deepseek-r1-1.5b \
--model /home/ubuntu/model/DeepSeek-R1-ReDistill-Qwen-1.5B-v1.0-Q6_K.gguf \
--host 0.0.0.0 \
--port 6006 \
--load-format gguf \
--gpu-memory-utilization 0.7 \
--max-model-len 1024 \
--max-num-seqs 1 \
--api-key E4nN90CJ8ISMihIWpaUalzmOTJ63S12Z
1.环境配置
- 内存:DDR5-4800HZ-32G
- CPU:I7-12700H-12核
- 硬盘:1T-SSD
- 显卡:NVIDIA RTX 3060 laptop 6G
- 推理框架:vLLM
- 模型:DeepSeek-R1-ReDistill-Qwen-1.5B-v1.0-Q6_K.gguf
2.安装 wsl
参考文章:Windows 安装 WSL 环境
5.进入 ubuntu
wsl -d Ubuntu-22.046.查看显卡信息
nvidia-smi
# 这时是没有的,输入完成后提示:
Command 'nvidia-smi' not found, but can be installed with:
apt install nvidia-utils-390 # version 390.157-0ubuntu0.22.04.2, or
apt install nvidia-utils-418-server # version 418.226.00-0ubuntu5~0.22.04.1
apt install nvidia-utils-450-server # version 450.248.02-0ubuntu0.22.04.1
apt install nvidia-utils-470 # version 470.256.02-0ubuntu0.22.04.1
apt install nvidia-utils-470-server # version 470.256.02-0ubuntu0.22.04.1
apt install nvidia-utils-535 # version 535.183.01-0ubuntu0.22.04.1
apt install nvidia-utils-535-server # version 535.216.01-0ubuntu0.22.04.1
apt install nvidia-utils-545 # version 545.29.06-0ubuntu0.22.04.2
apt install nvidia-utils-550 # version 550.120-0ubuntu0.22.04.1
apt install nvidia-utils-550-server # version 550.127.05-0ubuntu0.22.04.1
apt install nvidia-utils-510 # version 510.60.02-0ubuntu1
apt install nvidia-utils-510-server # version 510.47.03-0ubuntu3
# 为什么 WSL 里会“找不到 nvidia-smi”?
在 WSL2 中,NVIDIA 的架构是这样的:
Windows:
└── NVIDIA Driver(真正的内核驱动)
WSL2 Ubuntu:
├── libcuda.so ← 由 Windows 驱动透传
├── CUDA Toolkit
└── nvidia-smi ← 来自 nvidia-utils(需手动安装)
# 更新 apt
sudo apt update
# 安装 nvidia-utils,535 是目前 WSL + RTX 3060 非常稳的版本
sudo apt install -y nvidia-utils-535
# 验证
nvidia-smi7.安装 CUDA Toolkit
# 安装必要工具
sudo apt update
sudo apt install -y wget gnupg
# 添加 CUDA 仓库 pin
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
# 添加 NVIDIA GPG key
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/3bf863cc.pub
# 添加 CUDA 官方仓库
sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/ /"
# 更新索引
sudo apt update
# 安装 CUDA Toolkit
sudo apt install -y cuda-toolkit-12-1
# 配置环境变量
echo 'export PATH=/usr/local/cuda-12.1/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
# 验证
nvcc --version8.安装 Python
为了管理依赖和虚拟环境,推荐 Miniconda:
# 下载 Miniconda3(Linux 版本)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
# enter 键确认
# 输入 yes 完成安装
# 继续 enter 键确认,开始安装
# 输入 yes 开始初始化
# 使环境变量生效
source ~/.bashrc
# 验证
conda --version
# 接受使用条款,Anaconda 从 2023 年开始新增的 ToS(使用条款)确认机制,在非交互环境(WSL、脚本) 下必须手动接受
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/main
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/r
# 创建 deepseek独立环境
conda create -n deepseek python=3.11 -y
# 激活 deepseek python 独立环境
conda activate deepseek
# 激活成功后,会显示如下
# (deepseek) user@DESKTOP:~$9.安装 PyTorch
# 官方命令,前面大文件下载速度正常,后面小文件几 k、10 几 k/s 还经常断连,整个过程大概 60 分钟
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 验证 GPU
# 进入 python
python
import torch
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0))
# 示例
python
Python 3.11.14 (main, Oct 21 2025, 18:31:21) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
p>>> print(torch.cuda.is_available())
True
>>> print(torch.cuda.get_device_name(0))
NVIDIA GeForce RTX 3060 Laptop GPU # RTX 3060(我电脑使用的是 NVIDIA RTX 3060 Laptop 显卡)10.下载大模型
模型地址:huggingface 大模型,里面有 2000+ 模型
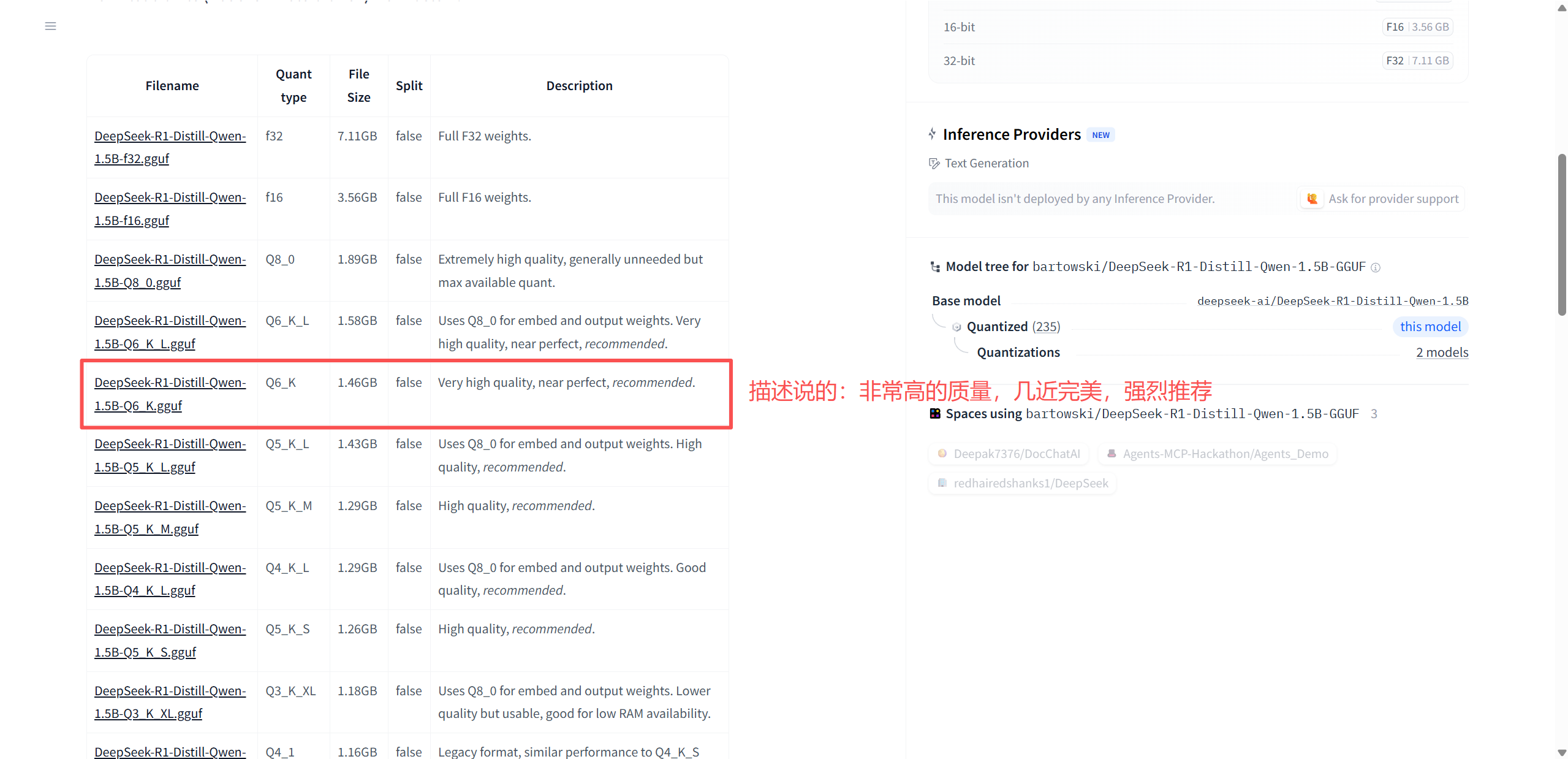
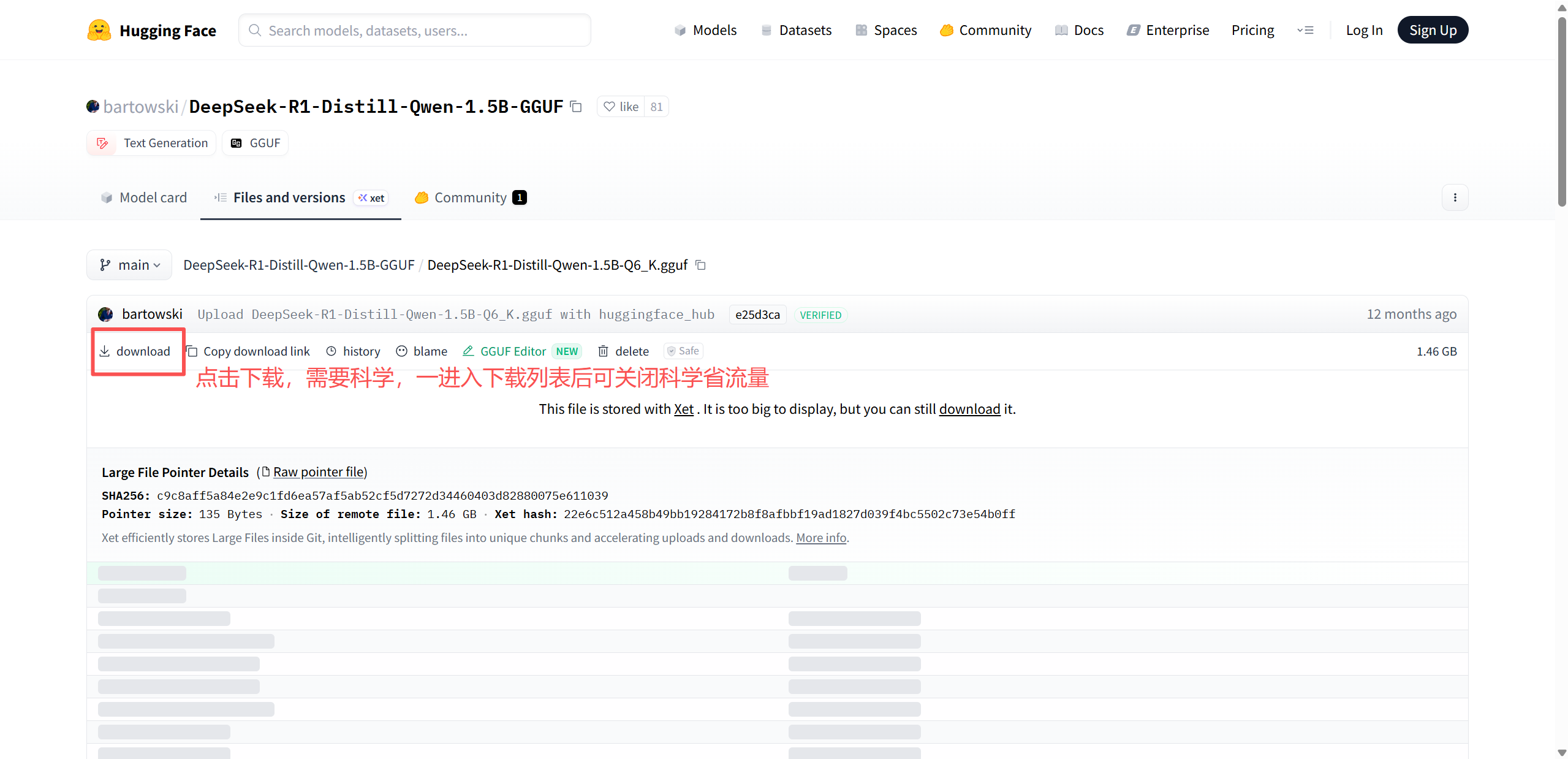
# 创建模型文件夹
mkdir -p /home/ubuntu/model
# 授权
chmod 777 -R /home/ubuntu/model
# 这时模型文件下载的目录例:C:\Users\xxx\Downloads,挂载宿主机的地址是/mnt/c
cp /mnt/c/Users/akim/Downloads/DeepSeek-R1-ReDistill-Qwen-1.5B-Q6_K.gguf /home/ubuntu/model11.安装推理框架
# 安装 vLLM 及其依赖项
pip install vllm --upgrade
# 设置环境变量,启用 vLLM v1
export VLLM_USE_V1=112.启动推理服务
部署大模型具有挑战性的部分是需要根据你自己的具体情况配置每个组件,有可能会频繁发生内存不足 (OOM) 错误,因此需要选择正确的模型并调整运行参数。
python -m vllm.entrypoints.openai.api_server \
--served-model-name deepseek-r1-1.5b \
--model /home/ubuntu/model/DeepSeek-R1-ReDistill-Qwen-1.5B-v1.0-Q6_K.gguf \
--host 0.0.0.0 \
--port 6006 \
--load-format gguf \
--gpu-memory-utilization 0.7 \
--max-model-len 1024 \
--max-num-seqs 1 \
--api-key E4nN90CJ8ISMihIWpaUalzmOTJ63S12Z- served-model-name:指定模型的名称。
- 例:--served-model-name deepseek-r1-1.5b
- model:DeepSeek 模型权重文件的路径。
- 例:--model /home/ubuntu/xxx.gguf
- host:主机 IP 地址
- 例:-- host 0.0.0.0
- port:访问端口
- 例:--port 6006
- load-format:指定加载格式,vLLM 在启动模型时,需要知道权重文件是什么格式,如果 vLLM 不指定 --load-format gguf,它会尝试当作 Hugging Face Transformers 模型去加载,启动过程就会出现:Repo id must be in the form 'repo_name' or 'namespace/repo_name'
- 例:--load-format gguf
- max-model-len:KV Cache,模型上下文长度。如果未指定,将继承模型自身配置。将max_model_len设置为2048、4096或8196,以找到在没有错误的情况下工作的最大值。如果取值过大,你可能会遇到OOM错误。
- 例:--max-model-len 2048
- max_num_seqs:用于配置同时处理多少个请求;由于这将使内存使用量增加一倍,因此最好将其设置为1。
- 例:--max_num_seqs 1
- trust-remote-code:加载 HuggingFace 自定义代码时必须启用。
- 例:--trust-remote-code
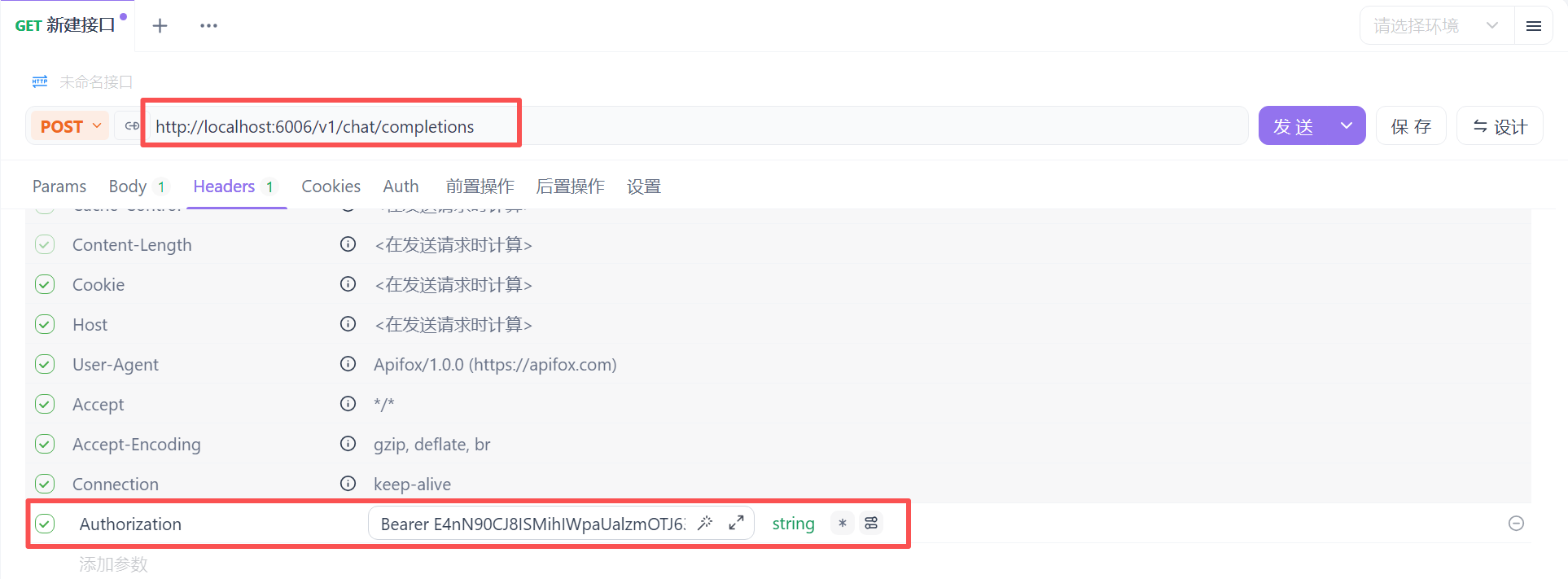
- api-key,用于设置API访问秘钥,保证自己的DeepSeek不会被随便访问,自行设置一个字符串即可;当后文部署的知识库应用访问DeepSeek推理服务器时,会检查其请求头中的 API 密钥。
- 例:--api-key E4nN90CJ8ISMihIWpaUalzmOTJ63S12Z
- dtype:权重和激活参数的数据类型,用于控制计算精度,常用 float16、bfloat16。
- 例:--dtype float16
- enforce-eager:用于启用 eager 模式,加快推理速度。
- 例:--enforce-eager
- enable-prefix-caching:重复调用接口时缓存提示词内容,以加快推理速度。例如,如果你输入一个长文档并询问有关它的各种问题,启用该参数将提高性能。
- 例:--enable-prefix-caching
- tokenizer:如前文所述,单独下载的 DeepSeek 分词器存储目录。
- 例:--tokenizer /home/ubuntu/xxx.json
- tensor-parallel-size:指定GPU数量。
- 例:--tensor-parallel-size 1
启动成功如下:
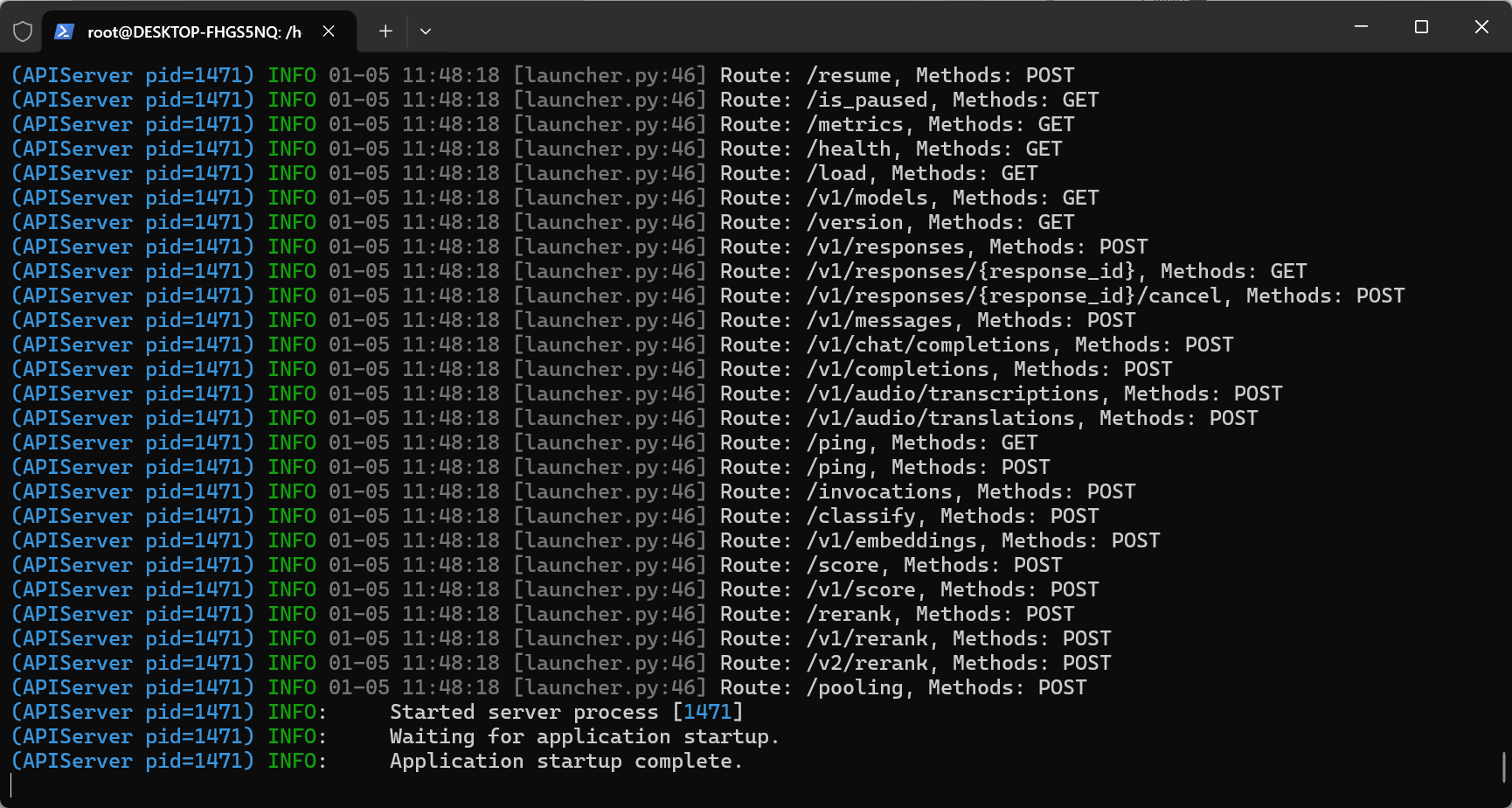
验证:
1.通过浏览器访问 http://localhost:6006/docs 查看 vLLM 支持的 DeepSeek API 接口。
2.curl 方式:
curl http://localhost:6006/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer E4nN90CJ8ISMihIWpaUalzmOTJ63S12Z" \
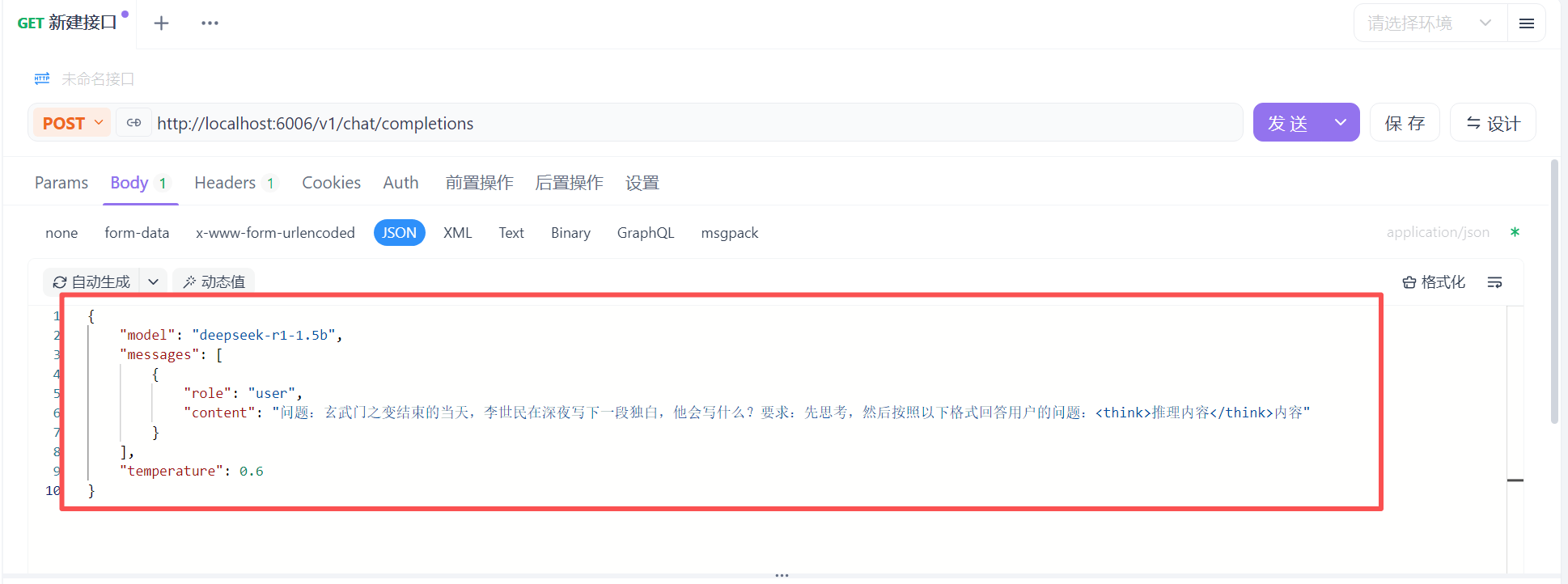
-d '{
"model": "deepseek-r1-1.5b",
"messages": [
{"role": "user", "content": "问题:玄武门之变结束的当天,李世民在深夜写下一段独白,他会写什么?要求:先思考,然后按照以下格式回答用户的问题:<think>推理内容</think>内容"}
],
"temperature": 0.6
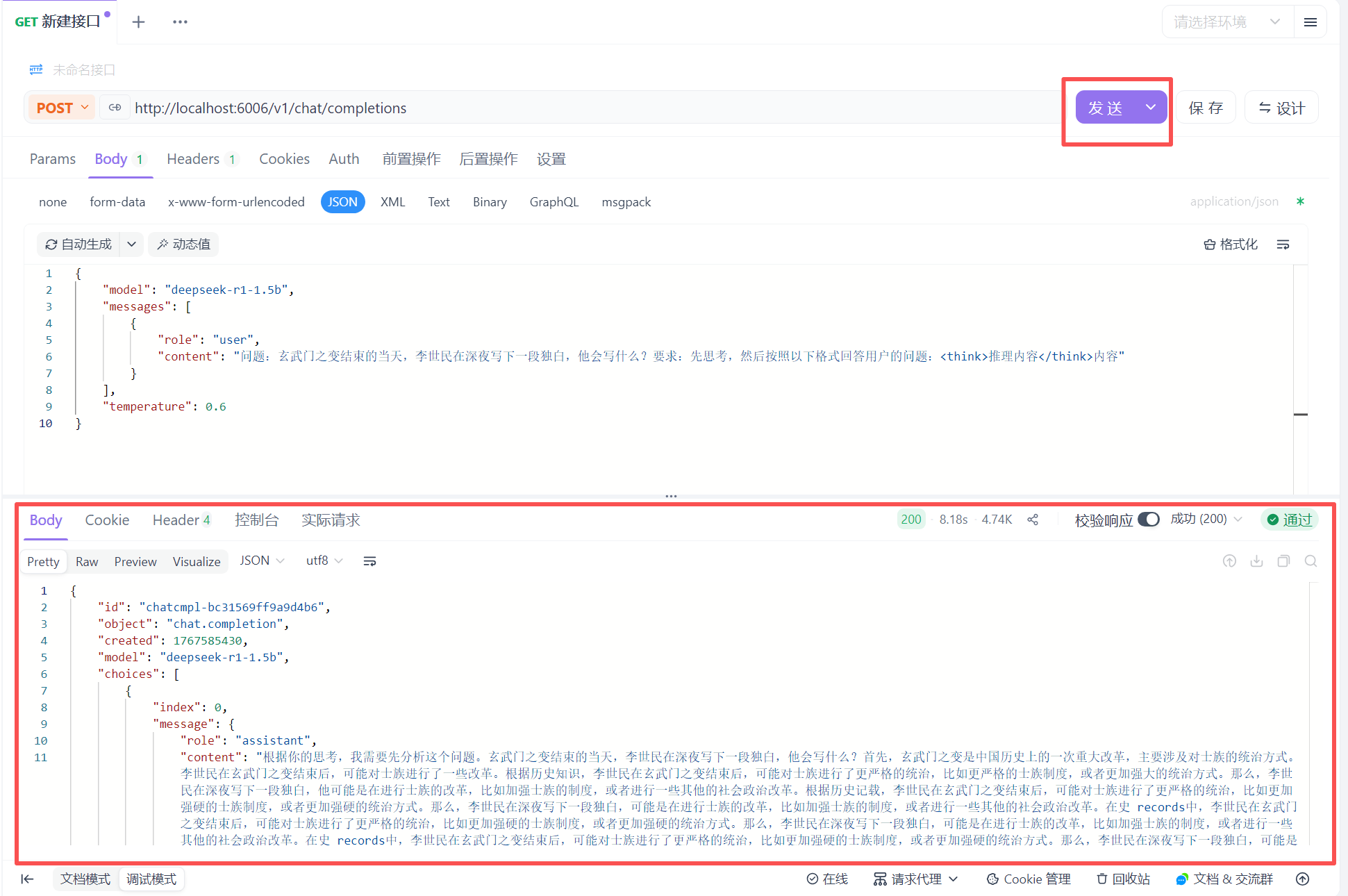
}'3.apifox/postman 方式:
13.安装知识库
一般情况下,大模型推理服务与应用服务不会部署在同一台服务器上。所以,准备一台服务器(可以是虚拟机,本文用 VM),采用 MaxKB 智能体平台。MaxKB支持企业快速接入主流大模型,高效构建专属知识库,并且提供从基础知识问答(RAG)、复杂业务流程自动化(Workflow,工作流)到智能体(Agent)的渐进式升级路径,有效赋能智能客服、智慧办公等多种应用场景。
# 安装 docker,自行搜索安装
# 拉取 MaxKB 镜像
docker pull registry.fit2cloud.com/maxkb/maxkb
# 运行 MaxKB 容器
docker run -d \
--name=maxkb \
--restart=always \
-p 8080:8080 \
-v /opt/maxkb/data:/var/lib/postgresql/data \
registry.fit2cloud.com/maxkb/maxkb待容器启动成功后,访问:http://192.168.67.11:8080(部署的虚拟机分配的IP为192.168.67.11)进入登录页面,首次登录后会要求设置新密码,然后再重新登录。
http://目标服务器 IP 地址:8080
默认登录信息
用户名:admin
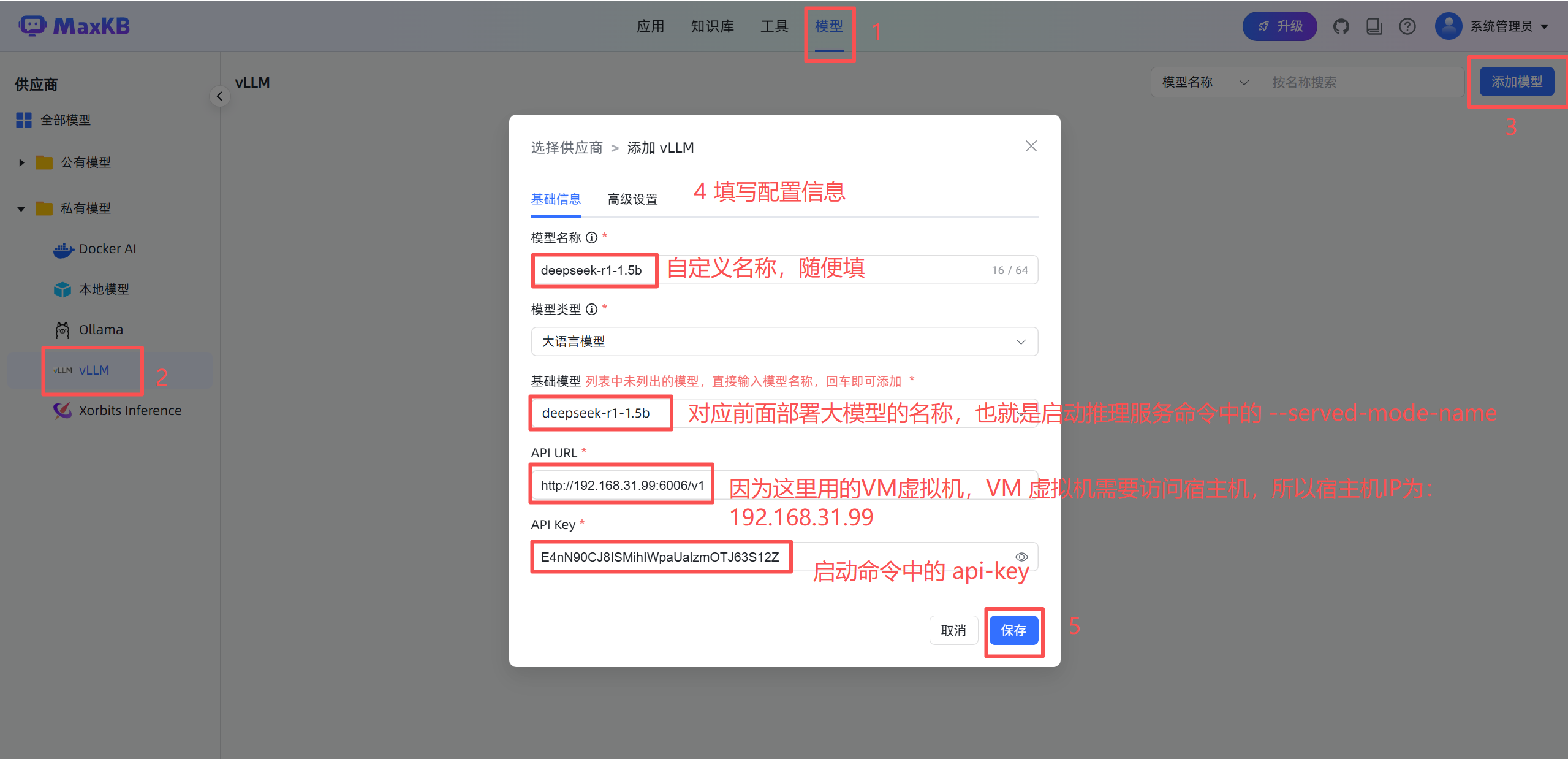
默认密码:MaxKB@123..14.知识库对接大模型
MaxKB 智能体平台登录成功后操作:
注意:
1.保存前需保证 vLLM 推理服务已启动
2.因为 MaxKB 是部署在 VM 虚拟机里的,需要访问宿主机 IP,但是宿主机用的 WSL,没有做转发,导致不管宿主机或 VM 虚拟机通过宿主机 IP 访问不了 vLLM 推理服务器接口,解决办法如下:
# 宿主机 power shell 通过下面命令查看端口绑定情况,看到的是 127.0.0.1:6006,这个是没有绑定到真实网卡,需要是 0.0.0.0:6006才可以
netstat -ano | findstr 6006
# TCP 127.0.0.1:6006 0.0.0.0:0 LISTENING 19584
# 添加端口转发,使用 power shell 执行以下命令
netsh interface portproxy add v4tov4 `
listenaddress=0.0.0.0 listenport=6006 `
connectaddress=127.0.0.1 connectport=6006
# 验证
netsh interface portproxy show all
# 能看到以下即可
侦听 ipv4: 连接到 ipv4:
地址 端口 地址 端口
--------------- ---------- --------------- ----------
0.0.0.0 6006 127.0.0.1 6006
15.服务编排
创建文件夹(可选) -> 创建应用 -> 高级编排 -> 创建
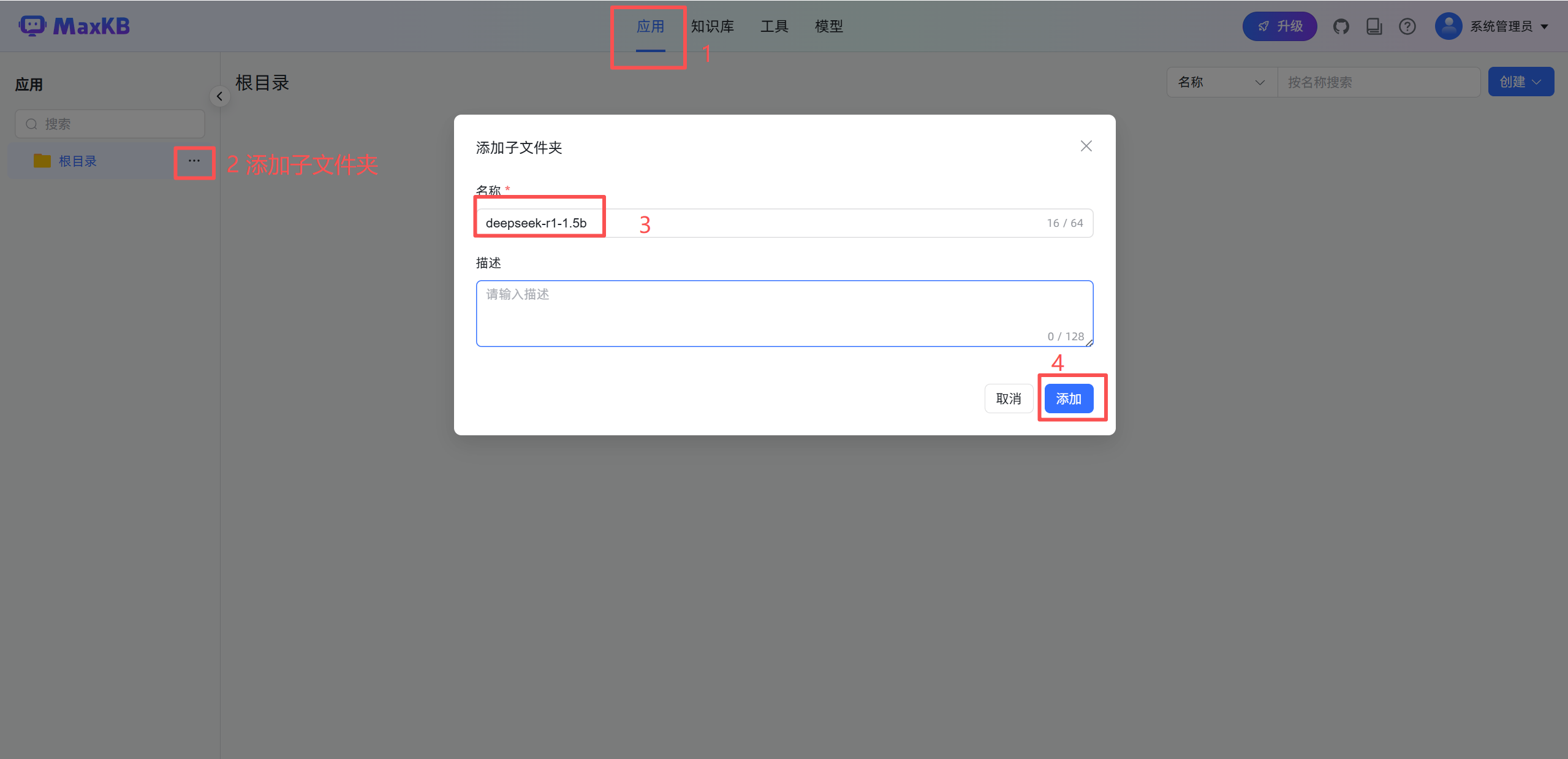
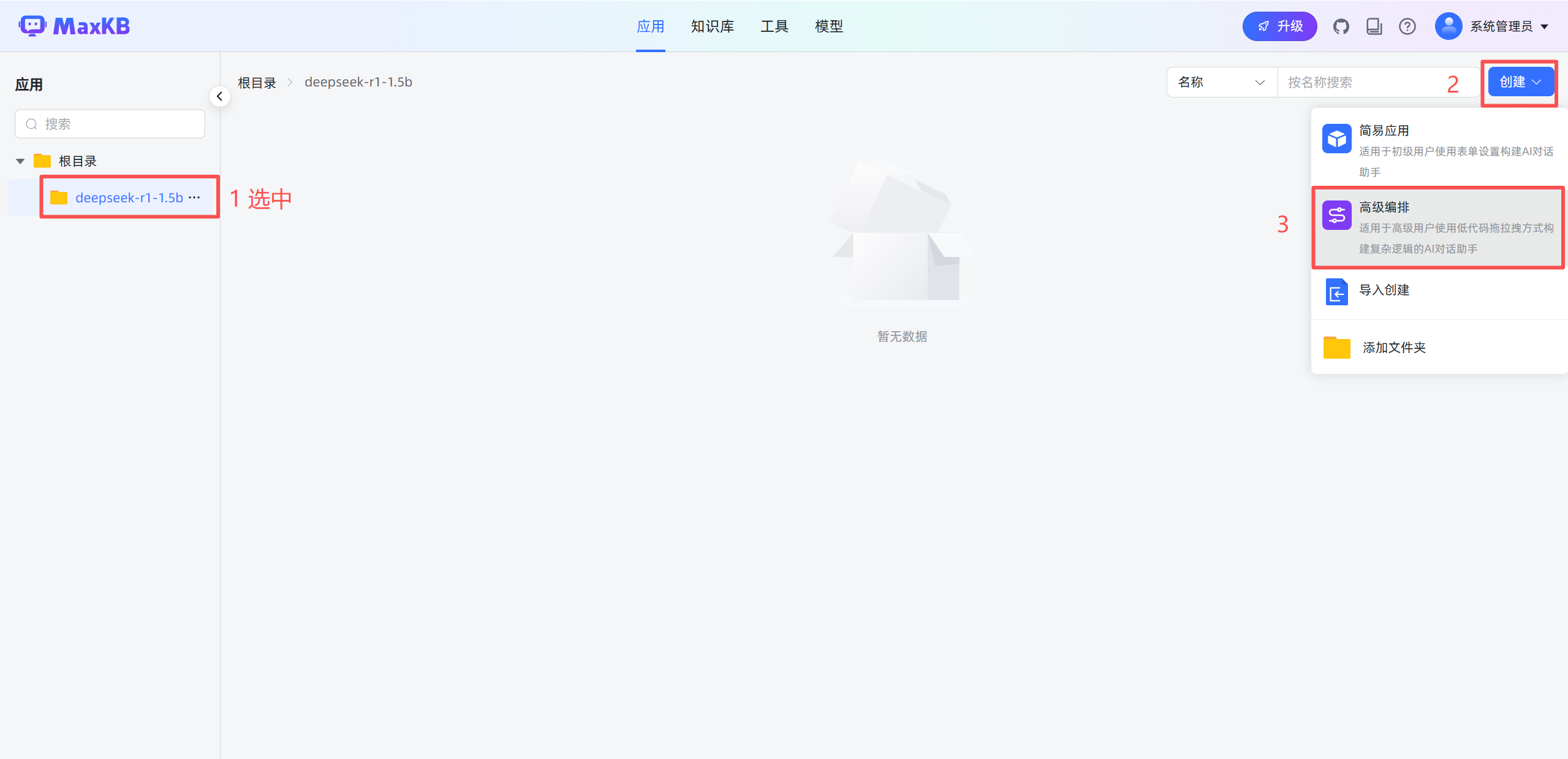
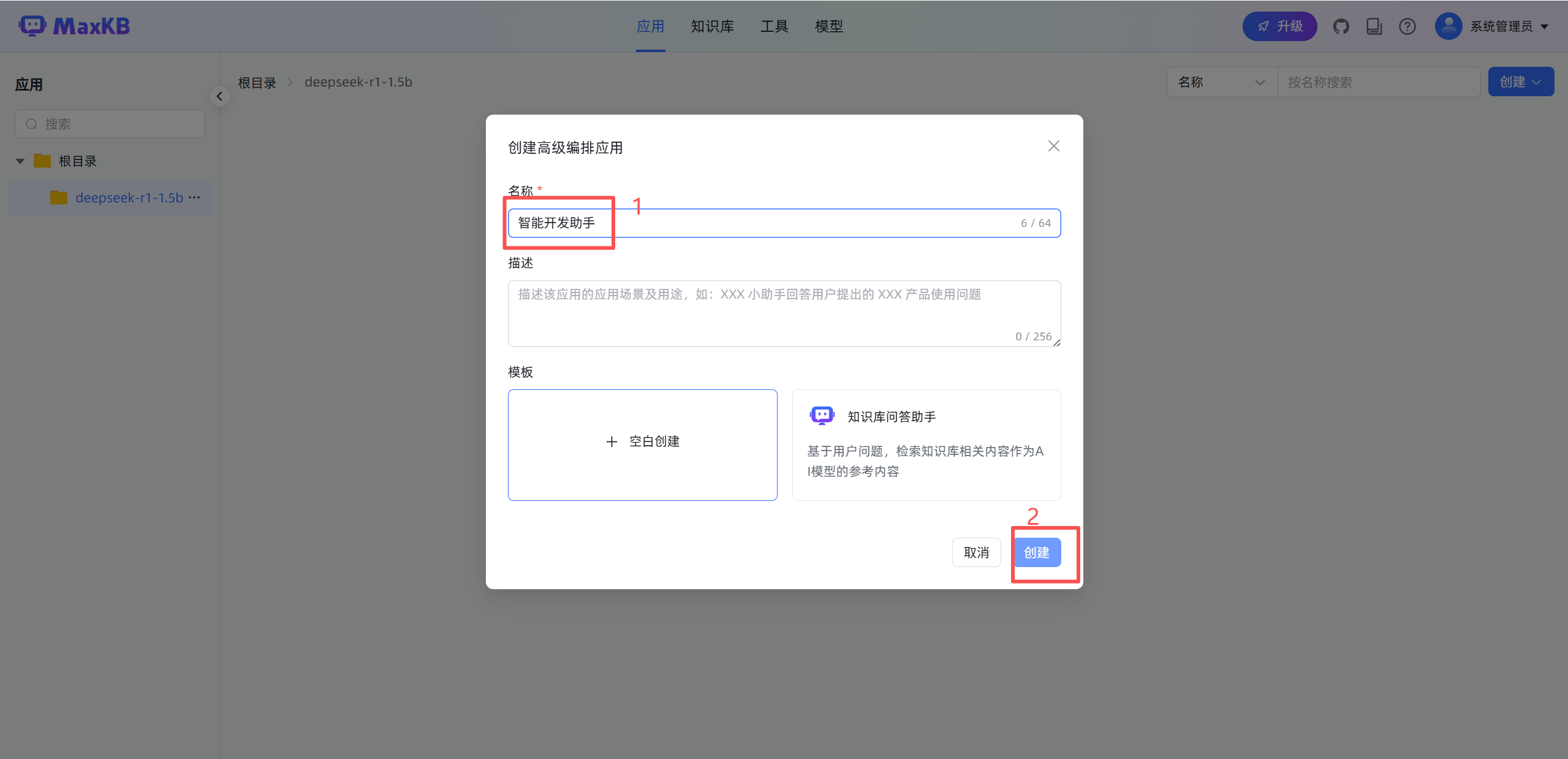
每个工作流都有基本信息与开始两个基础节点:
- 基本信息:应用的基本信息设置节点,如应用名称、描述、开场白等设置,每个应用只有一个基本信息节点,不能删除和复制。
- 开始节点:工作流程的开始,每个应用只能有一个开始节点,不能删除和复制。
使用方式参考文章:MaxKB 文档
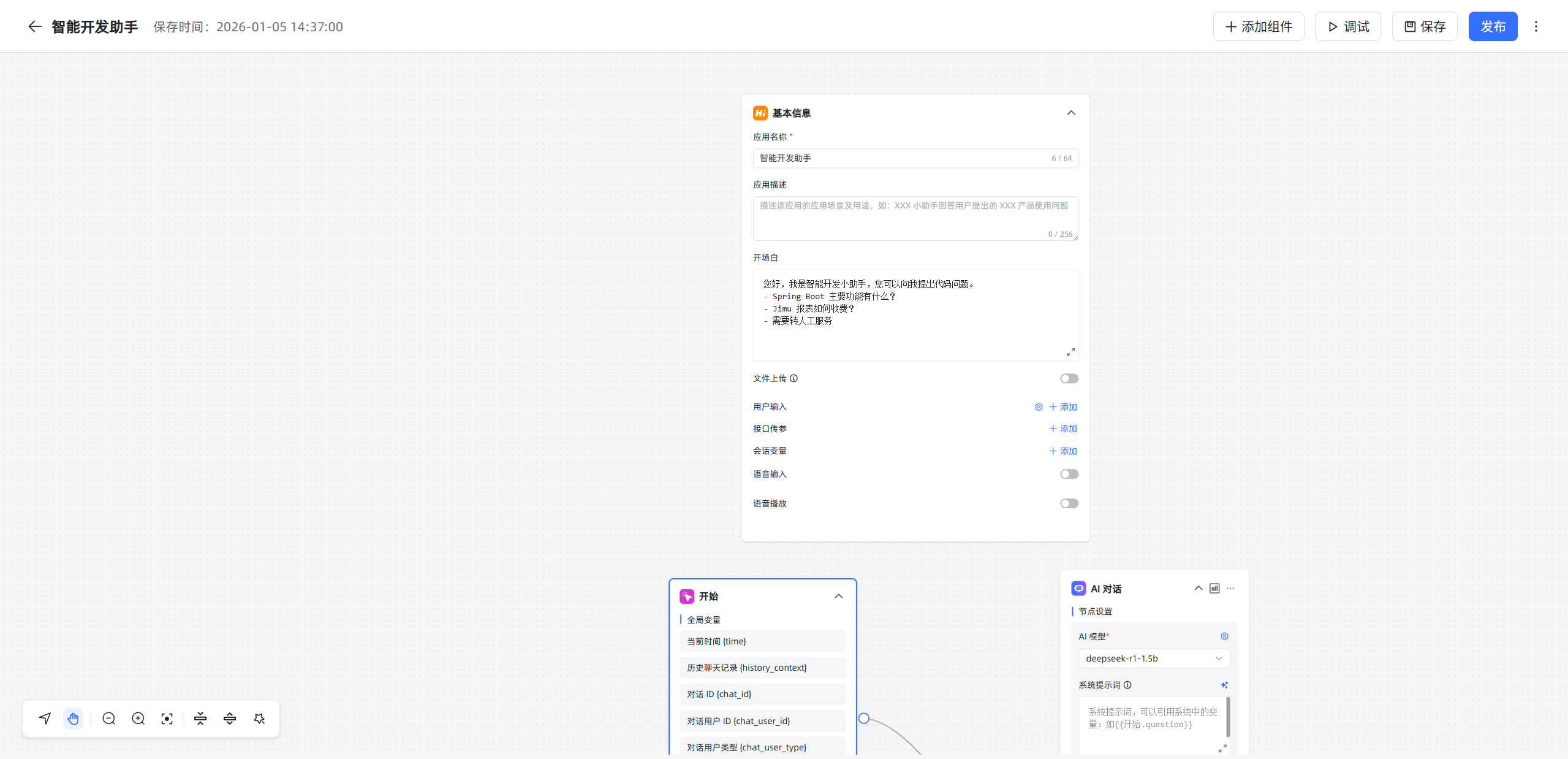
备注:
1.分词器下载方式
例:DeepSeek-R1-Distill-Qwen-32B